Zabbix 7 introduced some better support for SLAs. It also had better support for VMware.
VMware, of course now owned by Broadcom, has prioritized their Aria Operations (VROPS) monitoring suite over any of the alternative monitoring solutions (of which there is no shortage). Usually open source solutions have a limited life cycle as developers leave the project and move on to the next zen thing. Zabbix is still widely popular after many years. They got it mostly right the first time, and it absolutely excels at monitoring Linux.
To monitor VMware, it relies on VMware templates - and it used to present "objects" like datastores, as hosts. In version 7, it no longer does this, and instead tie the datastores as attributes of the true hosts - hypervisors, virtual machines, etc. This makes it a bit harder to monitor a datastore in an of itself - getting free space, used space, etc. if you want to do that. But - in version 7 there are now all kinds of hardware sensors and stuff that were not available in version 5. There are more metrics (items), more triggers that fire out of the box, etc.
One big adjustment in v7 is the support for SLAs. I decided to give it a shot.
The documentation only deals with a 3 node cluster. Such as a back-end cluster. That is not what I wanted.
What I wanted, was to monitor a cluster of hypervisors in each of multiple datacenters.
To do this, I started with SLAs:
- Rollup SLA - Quarterly
- Rollup SLA - Weekly
- Rollup SLA - Daily
Then I created a Service
- Rollup - Compute Platform
Underneath this, I created a Service for each data center. I used two tags on each one of these, one for datacenter and the other for platform (to future-proof in the even we use multiple platforms in a datacenter). Using an example of two datacenters, it looked like this.
- Datacenter Alpha Compute
- datacenter=alpha
- platform=accelerated
- Datacenter Beta Compute
- datacenter=beta
- platform=accelerated
These services have really nothing defined in them except the tags, and I assigned a weight of 1 to each of them (equal weight - we assume all datacenters are equally important).
Underneath these datacenter services, we defined some sub-services.
- Datacenter Alpha Compute
- Health
- Yellow
- Red
- Memory Usage
- CPU
- CPU Utilization
- CPU Usage
- CPU Ready
- Datastore
- Read Latency
- Write Latency
- Multipath Links
- Restart
We went into the trigger prototypes, and made sure that the datacenter, cluster and platform were set as tags so that all problems would have these tags coming in, necessary for the Problem Tag filter. We also had to add some additional tags to differentiate between severity warning and critical (we used level=warning for warnings, and level=high for anything higher than a warning).
On the problem tags filter, we wanted to catch only problems for our datacenters and this specific platform, so we used those two filters on every tag. In this example below, we have a cpu utilization service - a sub-service of CPU, which in turn is a sub-service of a datacenter.
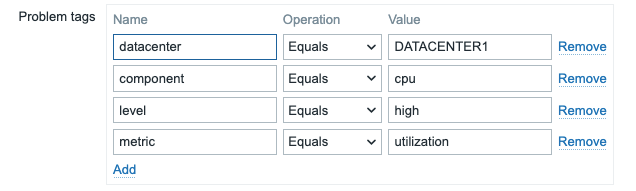
This worked fairly well, until we started doing some creative things.
First, we found that all of the warnings were impacting the SLAs. What we were attempting to do, was to put in some creative rules, such as:
- If 3 hypervisors or more in a cluster have a health = yellow, dock the SLA
- Use a weight of 9 on a health red, and a weight 3 on as situation where 3 hypervisors in a cluster have a health of yellow.
THIS DID NOT WORK. Why? Because unless every single hypervisor was a sub-service, there was no way to make it work because the rules all applied to child services. We couldn't have all of the hypervisors be a sub-service - too difficult to maintain, too many of them, and we were using Discovery which meant that they could appear or disappear at any time. We needed to do SLAs at the cluster level or the datacenter level, not individual servers (even though indeed we monitor individual servers, but they are defined through discovery).
So, we had to remove all warnings from the SLAs
- They were affecting the SLA too drastically (many hypervisors hit health=yellow for a while and then recover). We had to revert to just the red ones and assume that a health=red affects availability (it doesn't truly affect availability necessarily, but it does in certain cases).
- We could not make the rules work without adding every single hypervisor in every single datacenter as a sub-service which simply wasn't feasible.
The problem we now face, is that the way the SLAs roll up, the rollup SLA value is essentially the lowest of the SLA values underneath it.
- Platform SLA (weight 0) = 79.7 - huh?
- Datacenter A (weight 1) = 79.7
- Datacenter B (weight 1) = 99.2
- Datacenter C (weight 1) = 100
The platform SLA should be an average, I think, of the 3 datacenters if they are all equal-weighted. But that is not what we are observing.
The good news though, is that if Datacenter A has a problem with health=red, the length of time that problem exists seems to be counting against the SLA properly. And this is a good thing and a decent tactic for examining an SLA.
The next thing we plan to implement, is a separation between two types of SLAs:
- Availability (maybe we rename this health)
- Performance




